

Introduction – Reference Data vs. Master Data
It is very common for people to use ‘Reference Data’ and ‘Master Data’ interchangeably without understanding and appreciating the differences.
Reference data – External data that define the set of permissible values to be used by other data fields. Reference data gain in value when they are widely re-used and widely referenced. Typically, they do not change overly much in terms of definition, apart from occasional revisions. Example – Country Code, Asset Category, Vendor_ID and Currency Code, Industry Code, Security_ID (CUSIP, SEDOL, ISIN).
Master data – Internal dimensional data that directly participates in a transaction, like Customer_ID, Product_ID, Dept_ID and Employee_ID. Master data is critical for business and fall generally into four groupings: concepts, people, places, and things. Further categorizations within those groupings are called subject areas, domain areas, or entity types.
For example:
- Within concepts, there are deals, contracts, warranties, and licenses.
- Within people, there are customers, employees, and relationship managers.
- Within places, there are office locations and geographic divisions.
- Within things, there are products, business lines/units, and accounts.
Some domain areas may be further divided. Customer may be further segmented, based on relationships, market cap, incentives and history. A company may have normal customers, as well as premiere and executive customers. Product may be further segmented by sector, industry and geography/region.
The requirements and data life cycle for a product in the Financial Services Industry (FSI) is likely very different from those of the Insurance Industry. The granularity of domains is essentially determined by the magnitude of differences between the attributes of the entities within them.
Considerations – deciding why and what to manage
Master data is used by multiple applications, any error in master data will have ripple effect in all downstream applications consuming it. For example, an incorrect address in the customer master may mean orders, invoices/bills, confirms, and marketing literature are all sent to the wrong address. Similarly, an incorrect price on a Product Master can be a trade disaster, and an incorrect account number in an Account Master can lead to huge penalties.
Most organizations have more than one set of master data, this would be OK if it could be just union of the multiple master data sets, very likely some customers and products will appear in both sets of master data – usually, with different formats and different identifying keys. In most cases, customer IDs and product codes are assigned by the application that creates the master records, so the chances of the same customer or the same product having the same identifier in both databases is pretty remote.
Identifying master data entities is not complex, not all data that fits the definition for master data needs to be managed as such. The following criteria can be used to classify and identify master data attributes.
- Interactions: Master data are the nouns and transactional data are the verbs in the data interactions. Review of these interactions can be used to identify and define master data. Facts (verbs) and dimensions (nouns) are represented in the similar way in a data warehouse. For example, in trading systems, master data is part of the trade record. An employee reports to their manager, who in turn reports up through another employee ﴾hierarchical relationship). Products can be part of multiple market segments and roll ups.
- Data life cycle: Categorization of master data can be based on the way that it is created, read, updated, deleted, and searched. This data life cycle is different for different master‐data element types and industries. For example, how a customer is created depends largely upon business rules, industry segment, and data systems. There may be multiple customer creation paths, directly through customer on-boarding or through the operational systems. Additionally, how a customer element is created is certainly different from how a product element is created.
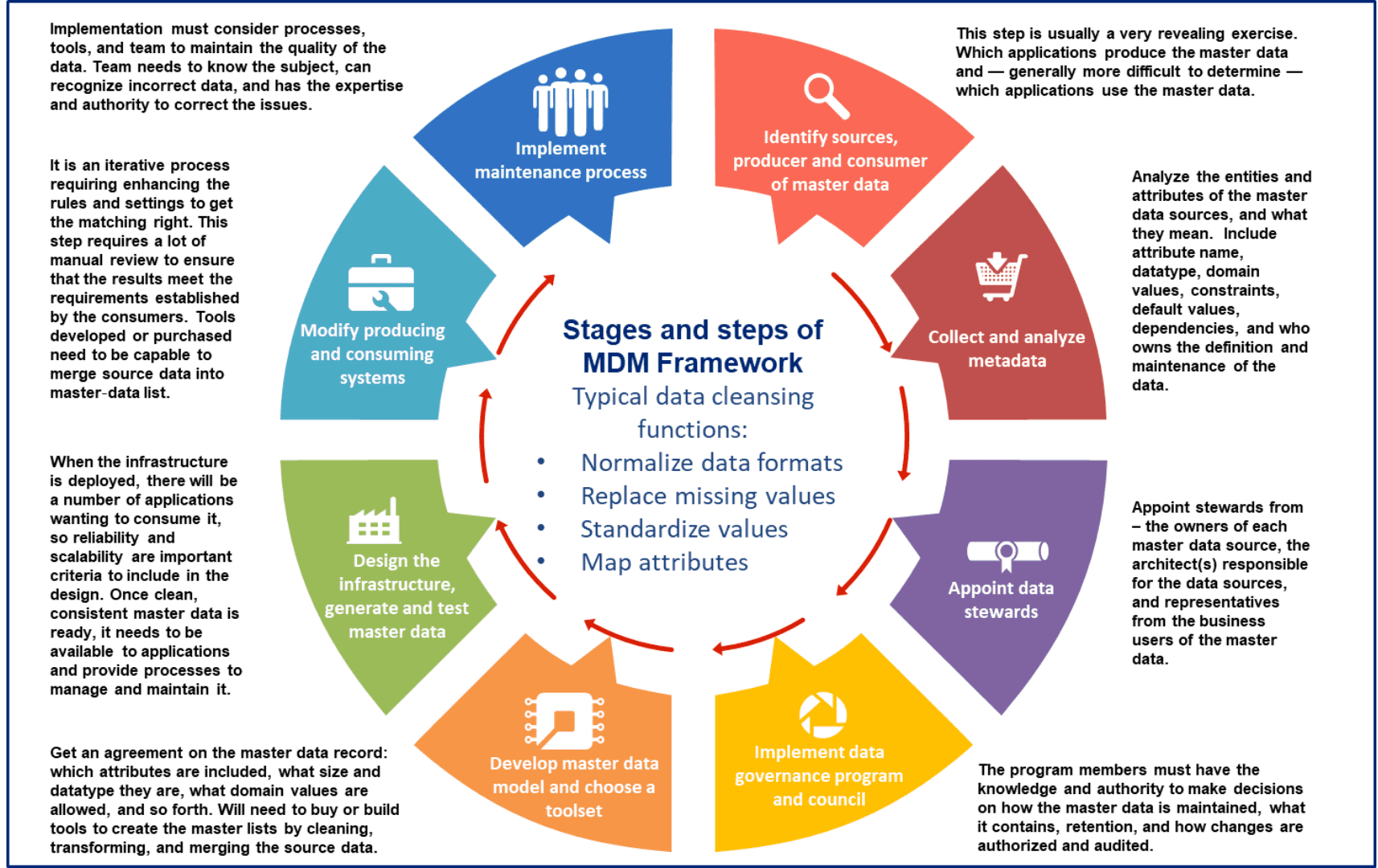
Framework
Arvind Joshi – Director, Data Management and Analytics Lead at Scotiabank
Arvind serves as the Data Governance Officer for U.S. Finance, and as such he is the primary point of contact for all U.S. Finance data matters including with Fed regulators. In his time with Scotiabank, Arvind has championed data as a strategic asset and participated in data governance team, project, and leadership meetings like US Data Council, US Operating Committee and US Finance Committee. His team is responsible for the execution of day-to-day data governance and management activities, remediation of data quality issues, and implementation of change management processes. His team works closely with U.S. Data Office colleagues to establish and maintain strong data management capabilities, such as data quality measurement and monitoring, data issue management, and data lineage.
ROLE DESCRIPTION
We are looking for a Membership Manager to join the company and take on one of the most opportunistic roles the industry has to offer. This is a role that allows for you to create and develop relationships with leading solution providers in the enterprise technology space. Through extensive research and conversation you will learn the goals and priorities of IT & IT Security Executives and collaborate with companies that have the solutions they are looking for. This role requires professionalism, drive, desire to learn, enthusiasm, energy and positivity.
Role Requirements:
Role Responsibilities:
Apex offers our team:
Entry level salary with competitive Commission & Bonus opportunities
Apex offers the ability to make a strong impact on our products and growing portfolio.
Three months of hands on training and commitment to teach you the industry and develop invaluable sales and relationship skills.
Opportunity to grow into leadership role and build a team
Extra vacation day for your birthday when it falls on a weekday
All major American holidays off
10 paid vacation days after training period
5 paid sick days
Apply Now >>